
Dynamic Model Selection
Automatically select the best-fit model for each request based on complexity, sensitivity, latency, and policy constraints.
Kalki Adaptive Routing
Optimize AI workloads dynamically across models based on cost, performance, latency, and compliance requirements.
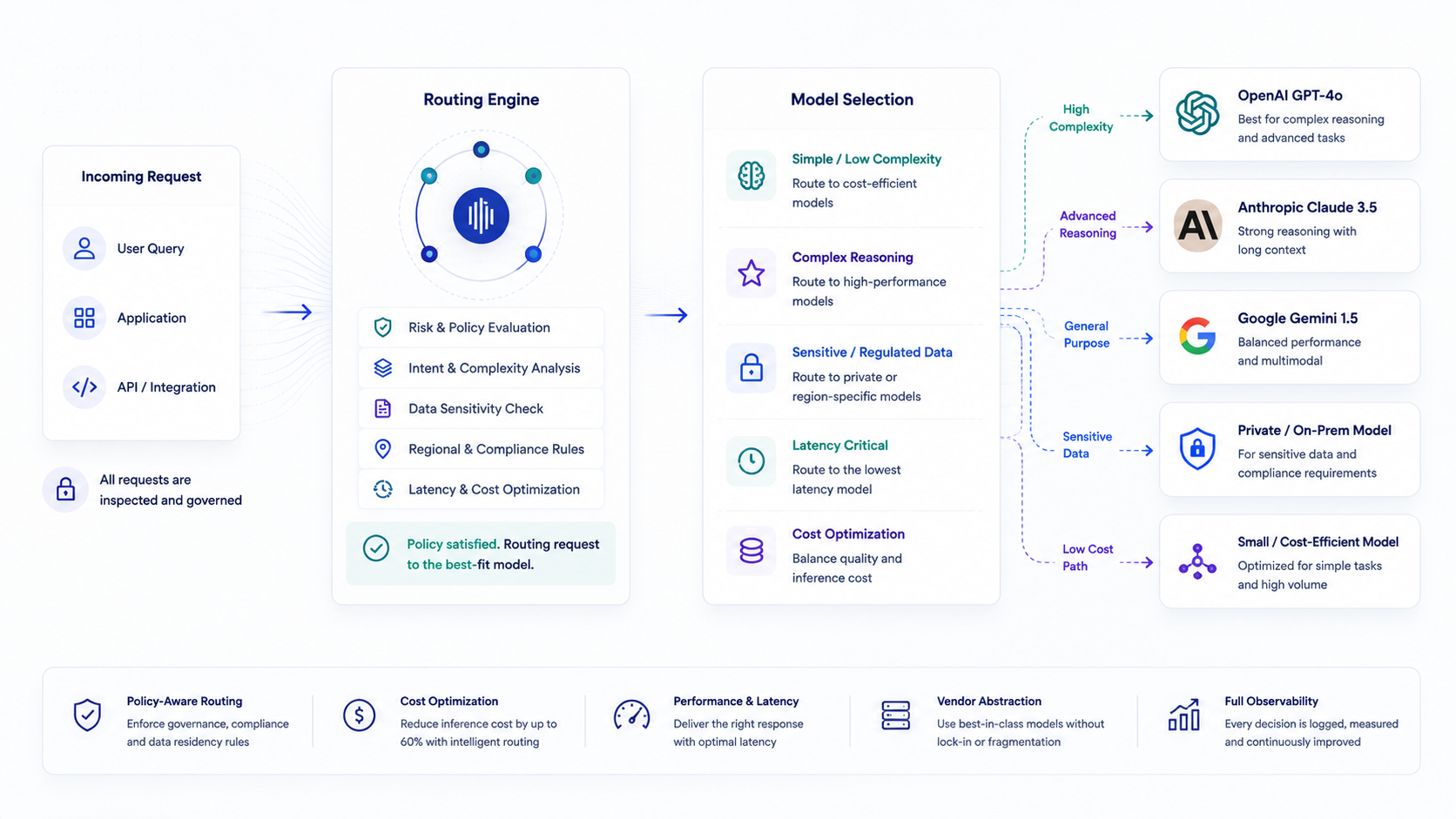
Adaptive Routing gives teams a governed decision layer for model selection, cost management, latency, data sensitivity, and provider flexibility.
Routing control surface
Kalki applies policy, sensitivity, cost, latency, and workload analysis to route each request to the best-fit model or private deployment.
Common routing challenges
Route simpler workloads to efficient models while preserving premium capacity for complex tasks.
Select lower-latency paths when response time is operationally important.
Send sensitive or regulated workloads to approved private or regional deployments.
Apply enterprise rules for geography, workload type, provider access, and model usage.
Automatically select the best-fit model for each request based on complexity, sensitivity, latency, and policy constraints.
Reduce inference costs by routing simpler workloads to lower-cost models while preserving premium capacity for high-value work.
Use OpenAI, Anthropic, Google, and private or open-source deployments through a unified governance layer.
Apply routing rules based on geography, sensitivity, workload type, and enterprise policies.
See how Kalki enables regulated enterprises to deploy AI safely, compliantly, and cost-effectively.
Request Free Demo